[기술서적]
[빅데이터를 지탱하는 기술] Chapter3.빅데이터의 분산 처리 - (1)
DH’s Blog
2023. 6. 1. 20:51
반응형

1. 대규모 분산 처리의 프레임워크
데이터 분야를 공부하다 보면 ‘구조화된 데이터’라는 표현을 한 번씩은 들어봤을 것이다. 데이터가 구조화 되어있다는 표현은 과연 어떤 의미일지 알아보자.
1-1. 구조화 및 비구조화 데이터
- 스키마 : 데이터베이스 테이블의 칼럼 명, 데이터 타입, 테이블 간의 관계 등을 정의한 구조
- 구조화된 데이터(structured data) : 스키마가 명확히 정의된 데이터
- 비구조화 데이터(unstructured data) : 스키마가 정해지지 않은 데이터
조금 더 쉽게 말하자면 데이터의 칼럼(column)이 없거나, 데이터의 타입이 정해져있지 않는 것과 같이 특정한 기준 없이 쌓이는 데이터를 비구조화 데이터라고 생각하면 된다.
1-2. 데이터 구조화 파이프라인
비구조화 데이터를 이용하고 분석하기 위해서는 구조화 데이터로 만들어주는 작업이 필요하다. 이를 위해 비구조화 데이터를 먼저 저장한 후에 구조화하는 작업을 진행하게 되는데, 이것을 데이터 구조화 파이프라인이라 한다.
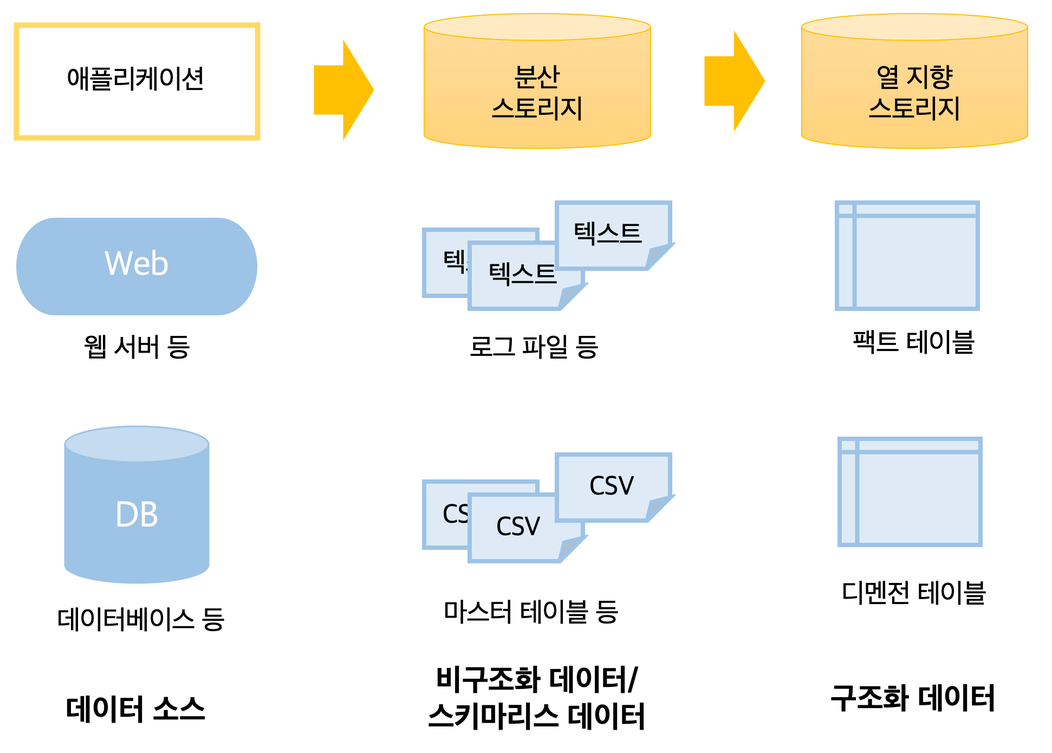
또한, 비구조화 데이터 → 열 지향 스토리지로 변환하는 과정에서 컴퓨터 리소스가 많이 소비된다. 이러한 상황에서 필요해진 것이 분산 처리 프레임워크(Hadoop, Spark, etc)이다.
열 지향 스토리지를 사용하는 이유?
- 열(column) 내에서는 유사한 데이터가 존재하므로 데이터를 매우 작게 압축할 수 있어서, 데이터의 압축률을 높이기 위해 열 지향 스토리지를 사용한다.
- 반드시 열 지향 스토리지를 사용하는 것은 아니고, 때로는 MPP 데이터베이스로 전송하기도 한다.
하둡(Hadoop)에서의 열 지향 스토리지
- 하둡은 사용자가 직접 스토리지 형식을 지정하고 원하는 쿼리 엔진에서 데이터 집계가 가능하다.
- Apache ORC - 구조화 데이터를 위한 하둡 열 지향 스토리지
- Apache Parquet - 스키마리스 데이터(비구조화 데이터)를 위한 하둡 열 지향 스토리지
2. 분산 처리 프레임워크 - Hadoop and Spark
2-1. Hadoop
Hadoop → 분산 파일 시스템(HDFS) + 리소스 관리자(YARN) + 분산 데이터 처리(MapReduce)

- HDFS : (분산 시스템의 스토리지 관리) 데이터를 항상 다수의 컴퓨터에 복사하여 저장
- YARN : CPU 코어, 메모리를 관리하는 리소스 매니저 (리소스 낭비없이 데이터를 처리하는 것이 목표!)
- CPU 코어와 메모리 집합 → 컨테이너(container)라 명칭
- 클러스터 내에서 비어 있는 호스트에게 컨테이너 먼저 할당하는 방식
2-2. Spark
- 기존의 MapReduce : 데이터 처리 과정에서 만들어진 중간 데이터 모두 디스크에 기록한다.
- Spark : 데이터 처리 과정에서 만들어진 중간 데이터는 메모리에 보존 하여 실행시간을 단축시킨다.
- Spark의 기능
- Spark SQL : Spark에서 SQL로 데이터를 처리할 수 있는 기능 제공
- Spark Streaming : Spark에서 스트림 처리를 할 수 있는 기능 제공
📘참고 서적: [빅데이터를 지탱하는 기술]
니시다 케이스케 지음 / 정인식 옮김
반응형