Apache Iceberg vs Apache Hive 차이점 - (2)
지난 시간에 Hive와 Iceberg의 차이점에 대해서 간단히 살펴보았다. 이번 시간에는 조금 더 기술적으로 어떤 부분이 다른지 알아보도록 하자.
[참고] 지난시간 내용
2023.11.03 - [[기술공부]/Data] - Apache Iceberg vs Apache Hive 차이점 - (1)
Apache Iceberg vs Apache Hive 차이점 - (1)
여러 시간에 걸쳐 Apache Iceberg의 구조와 특징에 대해서 하나씩 살펴보았다. 공부를 하다보니 문득 'Iceberg가 Hive 대비 어떤 장점을 가지고 나온 것일까'하는 궁금증이 생겼다. 그래서 이번 시간에
developers-haven.tistory.com
Hive와 차별되는 Iceberg 만의 특징
1. Snapshot
스냅샷은 특정 시점의 테이블 형상을 기록한 file을 가리키며, 스냅샷 기능을 통해 Iceberg는 특정 시점에 대한 rollback이 가능하다.
(1) 테이블 스냅샷 확인하는 방법
-- 테이블 스냅샷 조회(시점별 스냅샷에 대한 manifest list 확인 가능)
SELECT * FROM [스키마].[테이블명].snapshots;
| committed_at | snapshot_id | parent_id | operation | manifest_list | summary |
| 2023-10-30 03:29:51.215 | 29641004024753 | 51792995261850 | append | s3://…/table/metadata/snap-29641004024753-1.avro | { added-records -> 2478404, total-records -> 2478404, added-data-files -> 438, total-data-files -> 438, spark.app.id -> application_1520379288616_155055 } |
| 설명 | |
| committed_at | 스냅샷이 생성된 시간 |
| snapshot_id | 해당 스냅샷의 ID |
| parent_id | 해당 스냅샷의 부모가 되는 ID |
| manifest_list | 해당 스냅샷이 가지고 있는 manifest file 위치 정보를 가진 파일 |
| summary | 스냅샷에 일어난 변화에 대한 요약 정보 |
| operation | 변경된 내용에 따라 (append / replace / overwrite / delete) 값을 가짐 |
(2) 스냅샷을 이용해서 time travel 하는 방법
-- 2023년 10월 30일 01:22:00 시점으로 time travel
SELECT * FROM db.table TIMESTAMP AS OF '2023-10-30 01:22:00';
-- 스냅샷 ID가 '10963874102873'인 시점으로 time travel
SELECT * FROM db.table VERSION AS OF 10963874102873;
스냅샷에 대한 쿼리문은 아래 페이지를 참고하도록 하자.
https://iceberg.apache.org/docs/latest/spark-queries/
Queries
Spark Queries To use Iceberg in Spark, first configure Spark catalogs. Iceberg uses Apache Spark’s DataSourceV2 API for data source and catalog implementations. Querying with SQL In Spark 3, tables use identifiers that include a catalog name. SELECT * FR
iceberg.apache.org
2. Hidden Partition
파티션은 유사 행(row)들을 그룹화해서 해당 데이터에만 접근하여 쿼리 속도를 향상시키게 만들어준다. Hive의 경우, 파티션을 컬럼처럼 분명히 명시해줘야하고 아래 예시를 통해 이어서 설명해보겠다.
2-1. Hive 파티션 설명
먼저, 필요한 데이터를 적재(insert) 해준다.
INSERT INTO db.table PARTITION (event_date)
SELECT level, message, event_time, format_time(event_time, 'YYYY-MM-dd')
FROM unstructured_log_source; -- 소스 테이블
partition column & source column 관계
- partition column : event_date
- source column : event_time (소스 컬럼으로부터 파티션이 파생된다)
그리고 2023-10-30 일자의 오전 10~12시 사이 level, 데이터 건수를 조회해보자.
case1. 잘못된 예시
우리는 파티션, 소스 컬럼의 관계성을 알고 있다. 그렇기 때문에 소스 컬럼만을 가지고 자동으로 파티션 컬럼이 인식되어야 하지 않을까?(ex. 소스 컬럼 2023-10-30 10:00:00 → 파티션 컬럼 2023-10-30 인식) 이렇게 생각해서 아래 쿼리를 실행해보면 full table scan이 발생하고 파티션을 전혀 활용하지 못하는 것을 알 수 있다.
-- 잘못된 예시(파티션 조건 없이 full scan 발생)
SELECT level
, count(1) as count
FROM db.table
WHERE event_time BETWEEN '2023-10-30 10:00:00' AND '2023-10-30 12:00:00';
case2. 올바른 파티션 사용 예시
Hive는 파티션 컬럼을 명확히 지정해줘야만 이해를 하기 때문에, 파티션 컬럼과 소스 컬럼 간의 관계성을 인식하지 못한다.
-- 올바른 예시
SELECT level
, count(1) as count
FROM db.table
WHERE event_time BETWEEN '2023-10-30 10:00:00' AND '2023-10-30 12:00:00'
AND event_date = '2023-10-30'; -- 파티션 컬럼 명시
결국, Hive 파티션의 문제점은 아래와 같다.
1. 사용자의 실수로 다른 파티션 포맷을 사용하면 전혀 다른 쿼리 결과를 얻을 수 있다. (ex. 20231030 → 2023-10-30 는 전혀 다르다)
2. 테이블을 사용하기 위해 사용자는 테이블 레이아웃을 반드시 알고 있어야 한다.
이러한 Hive의 문제점을 해결할 수 있는 것이 Iceberg의 hidden partition 이다.
2-2. Iceberg hidden partition에 대하여
Hidden partition이란?
- 파티션 컬럼과 소스 컬럼 간의 관계성을 자동으로 인지하여, 주어진 컬럼값을 가지고 파티션을 생성해준다.
- 사용자가 파티션 컬럼을 직접 지정해주지 않아도 파티션 생성이 가능해서 hidden partition 이라고 한다.
- 이러한 기능이 가능한 것은 Iceberg에서는 metadata, data file이 따로 관리되기 때문이다.
-- Iceberg hidden partition
-- event_date에 대한 정보를 입력하지 않아도 두 컬럼의 관계성을 인식한다.
SELECT level
, count(1) as count
FROM db.table
WHERE event_time BETWEEN '2023-10-30 10:00:00' AND '2023-10-30 12:00:00'; -- event_date = 20231030으로 인식
Hidden partition의 장점
- 사용자가 테이블의 파티션을 관리하지 않아도 된다.
- 사용자가 테이블 레이아웃을 알지 못해도 쿼리 실행이 편리하여 user-friendly한 파티션 기능이다.
- 파티션 변경시 데이터를 rewrite 않아도 된다.
만약 파티션이 변경된다면 어떻게 될까?
상황) 2022년에는 월(month)단위 파티션을 사용하고, 2023년부터 일(day)단위 파티션으로 변경
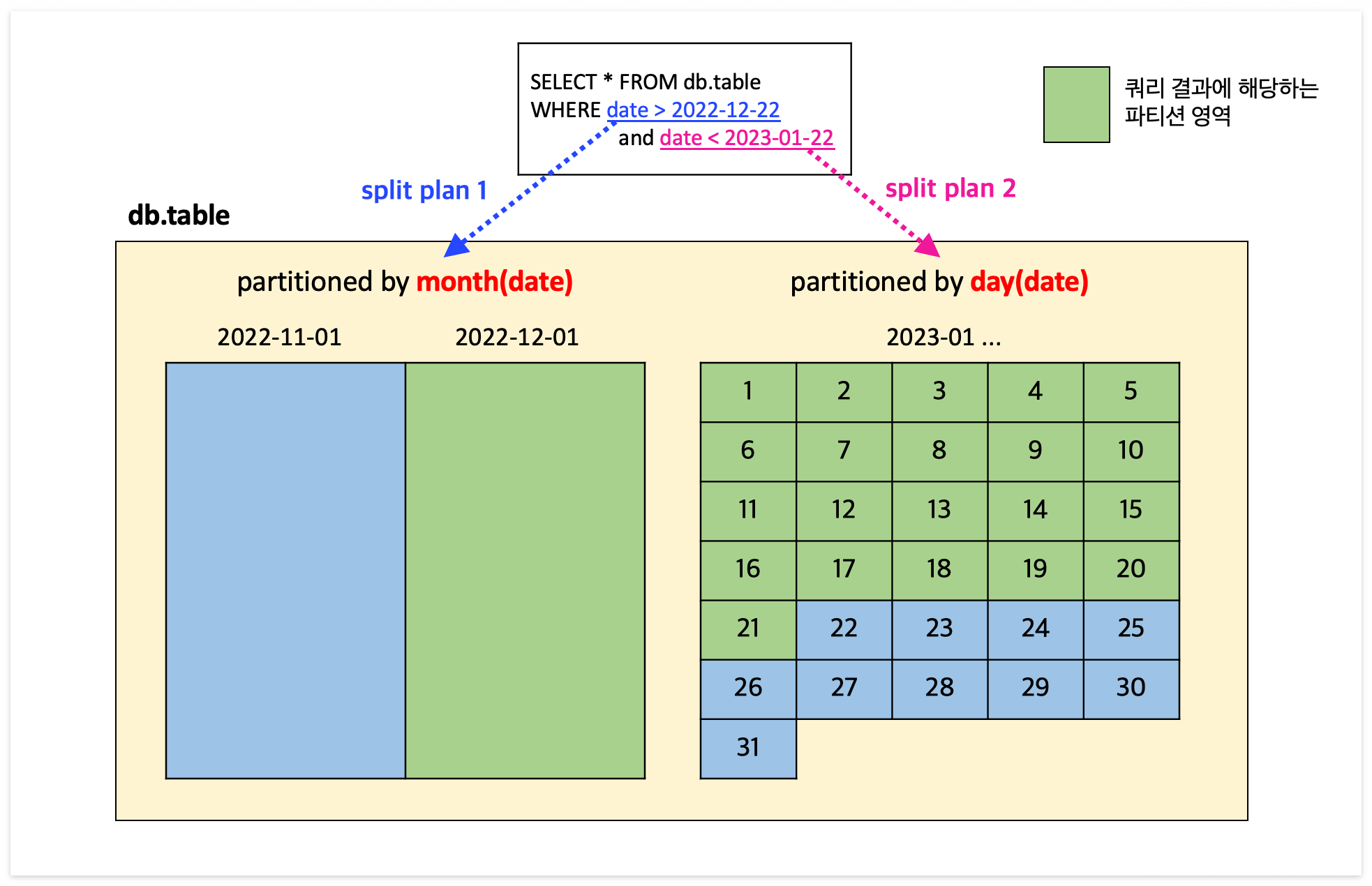
-- 파티션 변경 전,후의 데이터를 모두 조회하는 상황
SELECT *
FROM db.table
WHERE date > 2022-12-22 -- 파티션 변경 전의 month 단위 파티션 기준으로 Plan
AND date < 2023-01-22; -- 파티션 변경 후의 day 단위 파티션 기준으로 Plan
파티션 변경 후 Select 결과
- 파티션 변경 전의 old data & metadata file은 영향을 받지 않고, 이전과 동일하게 파티션 사용이 가능하다.
- 파티션 변경 후 write된 data는 변경된 파티션 구조로 저장되고 관련된 metadata file도 생성된다. (이전 파티션에 대한 metadata와 별도로 관리)
- 두 파티션의 메타데이터가 따로 관리되며 만약 파티션 변경 전후의 데이터를 동시에 조회하는 경우, 자동으로 plan을 나눠서 실행해준다. (→ split plan)
3. Metadata
Iceberg는 테이블 형상이 metadata file로 관리되고, 테이블 스키마에 변경이 생기면 새로운 metadata file이 만들어져서 기존의 것을 대체하게 된다. metadata file은 스키마, 파티션, 스냅샷 등에 대한 정보를 모두 가지고 있다. (참고로 Hive는 MetaStore에서 메타데이터를 관리하여 RDB 스토리지 부하 문제가 발생할 수 있다) 메타데이터에 대한 설명은 아래 페이지에 자세히 정리해두었으니 참고하길 바란다.
[참고] Iceberg metadata에 대하여
2023.10.11 - [[기술공부]/Data] - Apache Iceberg란 무엇일까?
Apache Iceberg란 무엇일까?
현재 빅데이터 솔루션 기업에서 Data Architect로 근무하면서, 새로운 기술이 우리 회사의 솔루션에 적용될때마다 자연스레 많은 기술 공부의 기회를 얻고 있다. 작년에 진행한 프로젝트에서 Iceberg
developers-haven.tistory.com
Hive와 Iceberg는 모두 대용량 데이터를 효율적으로 저장하고 사용하기 위해 등장한 기술이다. 어떤 기술이 더 뛰어나는지에 대한 질문 보다는 상황에 필요한 기술이 무엇인지(ex. 벌크 단위의 대규모 배치인지, 실시간 수집성 데이터인지)를 생각해보고 고를 수 있을 것이다. 오늘도 이 내용이 많은 사람들에게 도움이 되었으면 좋겠다.
참고사이트
1. https://www.linkedin.com/pulse/hive-vs-iceberg-choosing-right-big-data-technology-your-pottammal/
2. https://www.analyticsvidhya.com/blog/2022/09/how-apache-iceberg-works-with-partitioning/