1. HDFS(Hadoop Distributed File System)
HDFS(하둡분산파일시스템)란?
- 데이터를 블록(block) 단위로 나뉘어 분산 저장하는 파일 시스템을 의미한다.
- 버전에 따라 기본적인 블록 사이즈는 64MB~256MB이며 원하는 블록 사이즈로 설정할 수 있다.(아래 예시에서는 블록 사이즈가 128MB이라고 가정하고 설명하겠다)
- 블록 사이즈 보다 작은 파일은 그대로 저장하며, 블록 사이즈 보다 큰 파일은 블록 단위로 나누어 저장하게 된다.(아래 예시 참고)
블록에 대해서 조금 생소할 수 있지만 아래 그림을 한번 참고해보자.
356MB 크기의 파일이 저장될 때 블록 사이즈가 128MB라면 해당 파일은 3개의 블록(128MB + 128MB + 100MB)으로 나뉘어 저장된다. 조금 더 풀어서 설명하자면 파일을 특정 사이즈 단위로 쪼개서 저장하는데 쪼개진 한 단위가 블록이 되는 것이다. 파일을 블록 단위로 나누는 이유 중 하나는 단일 디스크의 용량 보다 큰 파일을 저장할 수 있는 용이함 때문이다.

결국 해당 파일은 지정한 크기의 3개 블록으로 나눠지게 된다.(이해하기 쉽게 색깔로 블록을 구분하였음) 그리고 각 블록이 3개로 복사되어 저장되는 것을 볼 수 있는데, 이에 대해 알아보도록 하자. 참고로 데이터 노드(Data Node)에 대해서는 아래에 이어서 설명할 예정이며 우선 블록이 저장되는 곳이라는 정도만 알고 넘어가자.
HDFS 3copy란?
- 블록을 3개로 복제하여 서로 다른 서버에 저장함으로써 장애 복구가 가능하고 데이터 유실을 방지할 수 있다.
- 대신 동일한 블록을 3개로 저장하다보니 HDFS 용량이 부족해질 수 있다는 문제가 있다.
2. 네임노드와 데이터 노드
HDFS 아키텍처(구조)는 하나의 네임 노드(Name Node)와 여러 개의 데이터 노드(Data Node)로 구성되어 있다. 네임 노드와 데이터 노드가 무엇인지 자세히 알아보도록 하자.
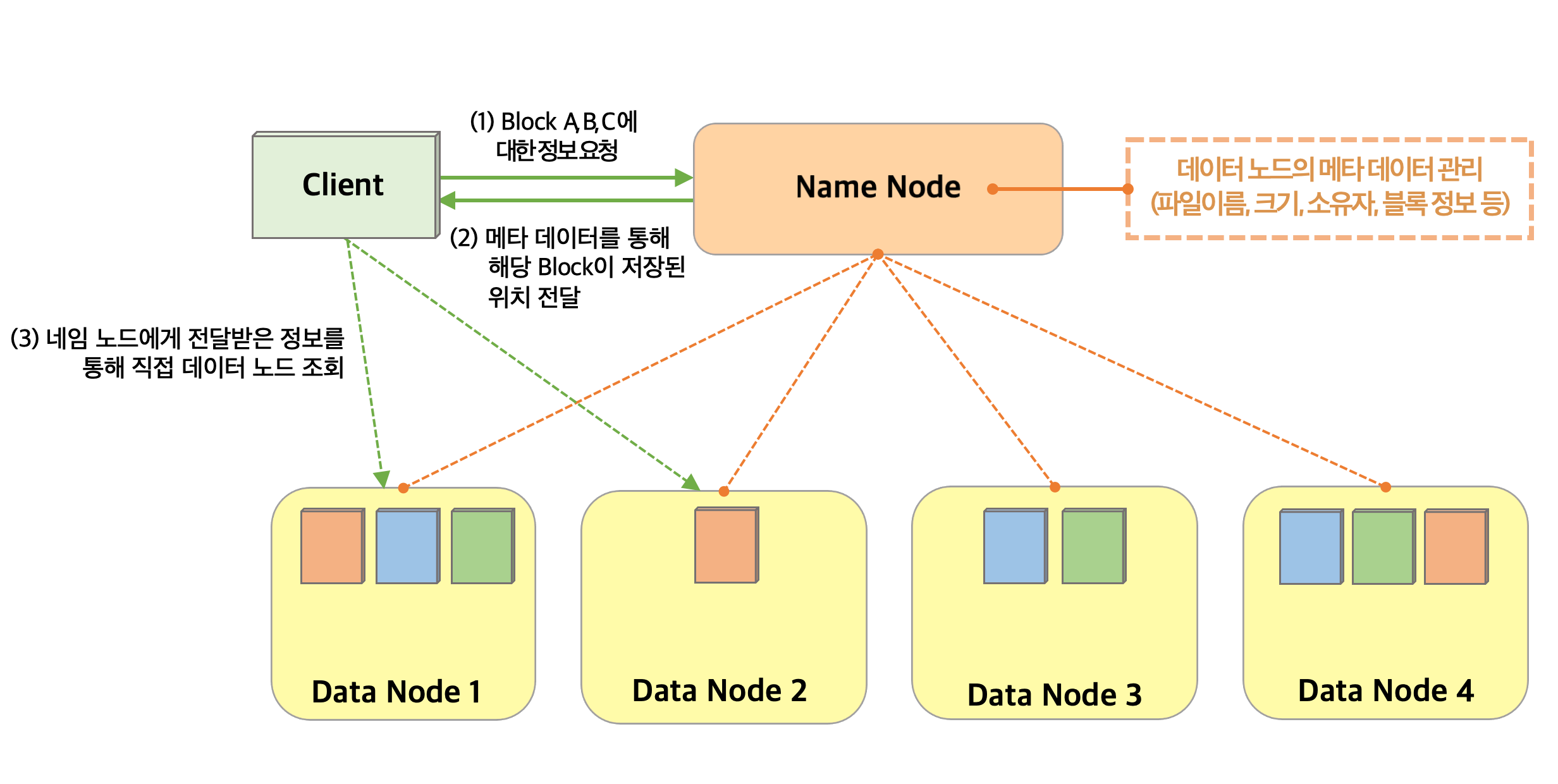
네임 노드(Name Node)란?
- 메타 데이터를 통해 데이터 노드를 관리하는 주체(메타 데이터는 데이터 파일에 대한 정보와 블록 위치를 매핑하고 있는 데이터를 의미)
- 데이터 노드는 주기적으로 본인의 활성상태(=하트비트, 3초 간격)와 블록 리포트(6시간 간격)를 네임 노드에게 전달하고, 네임 노드는 이를 전달받아 데이터 노드의 상태를 관리한다.
데이터 노드(Data Node)란?
- 실제로 파일을 블록 단위로 나눠서 저장하고 있는 곳이다.(첫번째 그림에서 블록이 데이터 노드에 저장되어 있다고 했던 부분)
- 주기적으로 네임 노드에게 본인의 상태(=하트비트)를 전달하여 활성 상태(Live or Dead)를 알려준다.
쉽게 설명하자면 데이터 블록에 대한 정보(ex.파일이름/크기/접근권한/블록 정보 등)는 네임 노드가 관리하고, 실제 블록의 데이터는 데이터 노드에서 저장하고 있는 것이다. 네임 노드가 있기 때문에 어떤 데이터를 찾고 싶을 때 굳이 모든 데이터를 스캔하지 않고, 해당 데이터에 대한 위치 정보를 받아 쉽게 데이터를 읽고 쓸 수 있게 된다. HDFS는 데이터를 안전하게 보관하기 위해 다양한 기능을 제공하는데 이에 대해서 더 알아보도록 하자.
3. HDFS 기능
1. HDFS Trash
- HDFS에서 삭제한 파일은 우선 Trash 디렉토리로 이동되고 일정 기간이 지난 후에 실제 파일이 삭제된다.(사용자의 실수에 의한 삭제를 방지하기 위함)
- 이때, Trash 디렉토리는 사용자가 지정한 간격으로 체크 포인트(check point)가 생성되고 해당 기간이 지나면 파일이 삭제되어 블록을 해제 후 반환하게 된다.
2. HDFS 밸런서(Balance)
- 일부 데이터 노드에만 데이터가 집중되어 노드 간의 데이터 불균형이 발생하면 밸런싱 작업을 통해 노드 간의 데이터 균형을 맞춰준다.
- 데이터 노드를 추가하거나 대량의 데이터를 삭제 및 추가하는 경우 특정 노드에만 데이터가 집중될 수 있는데, 이때 밸런싱 작업을 통해 노드 간의 데이터 균형을 맞춰주게 된다.
3. HDFS 이레이저 코딩(Eraser Coding)
- 3copy(블록을 3개의 복제본으로 관리)를 유지하다보면 사용 빈도가 없는 데이터(cold data)에 대해서도 불필요한 리소스를 사용하게 되는데, 이를 해결하기 위한 방법이 이레이저 코딩이다.
- 3copy 대신 Reed-Solomon 알고리즘 방식을 적용하여 n개의 block -> (알고리즘을 이용한 인코딩) -> k개(n보다 작음)의 block으로 저장해주고, 필요시 다시 디코딩을 통해 원본 데이터로 복구해준다.
데이터가 자산이란 말이 있듯이 요즘 대부분의 기업은 방대한 양의 데이터를 저장하고 싶어 하고 이러한 니즈에 따라 빅데이터 환경도 계속 발전해나가고 있다. 이러한 빅데이터 환경의 가장 기본이 되는 것이 하둡(Hadoop)인데, 하둡에서 데이터 파일을 저장하고 있는 시스템이 HDFS인 것이다. 그래서 하둡을 공부하기 전에 HDFS에 대해서 먼저 공부해봤고 이 내용을 공부하는 사람들에게 많은 도움이 되었으면 좋겠다.
참고: [빅데이터-하둡,하이브로 시작하기] WikiDocs
https://wikidocs.net/book/2203
'[기술공부] > BigData' 카테고리의 다른 글
| Hive(하이브)에 대하여 (0) | 2023.08.23 |
|---|---|
| Hadoop(하둡)에 대하여 (0) | 2023.08.22 |
| Hive MetaStore(메타스토어) 활용방법 - (2) (1) | 2023.08.03 |
| Hive MetaStore(메타스토어) 활용방법 - (1) (2) | 2023.08.03 |
| Hive MetaStore(메타스토어)에 대하여 (0) | 2023.08.03 |