Hadoop(하둡)에 대하여
하둡이란 무엇일까?
빅데이터 환경에서 일을 하다보면 Hadoop(하둡)에 대해서 한번쯤은 들어보거나 실제 하둡 환경에서 작업해봤을 것이다. 하둡에 대한 가장 보편적인 정의는 프로그래밍을 통해 컴퓨터 클러스터에서 대규모 데이터를 분산 저장 및 처리할 수 있는 프레임워크이다. 데이터를 분산 처리하면서 데이터 분석을 위한 비용과 시간을 단축시킬 수 있었고, 하둡의 등장으로 빅데이터 분석이 본격적으로 시작되었다. 시간이 지나면서 데이터를 더 효율적으로 처리하기 위해 하둡 버전도 기능을 업그레이드했고, 22년 말 기준으로 버전3(v3)까지 공개되었다.
하둡의 가장 큰 특징은 '분산 저장과 처리'라고 할 수 있는데 처음 접하는 사람에겐 조금 생소한 표현일 수 있다. 이를 좀 더 자세히 이해하기 위해서 하둡의 버전별 구조(architecture)에 대해서 알아보자.
Hadoop V1 (데이터 분산 저장 + 병렬 처리)
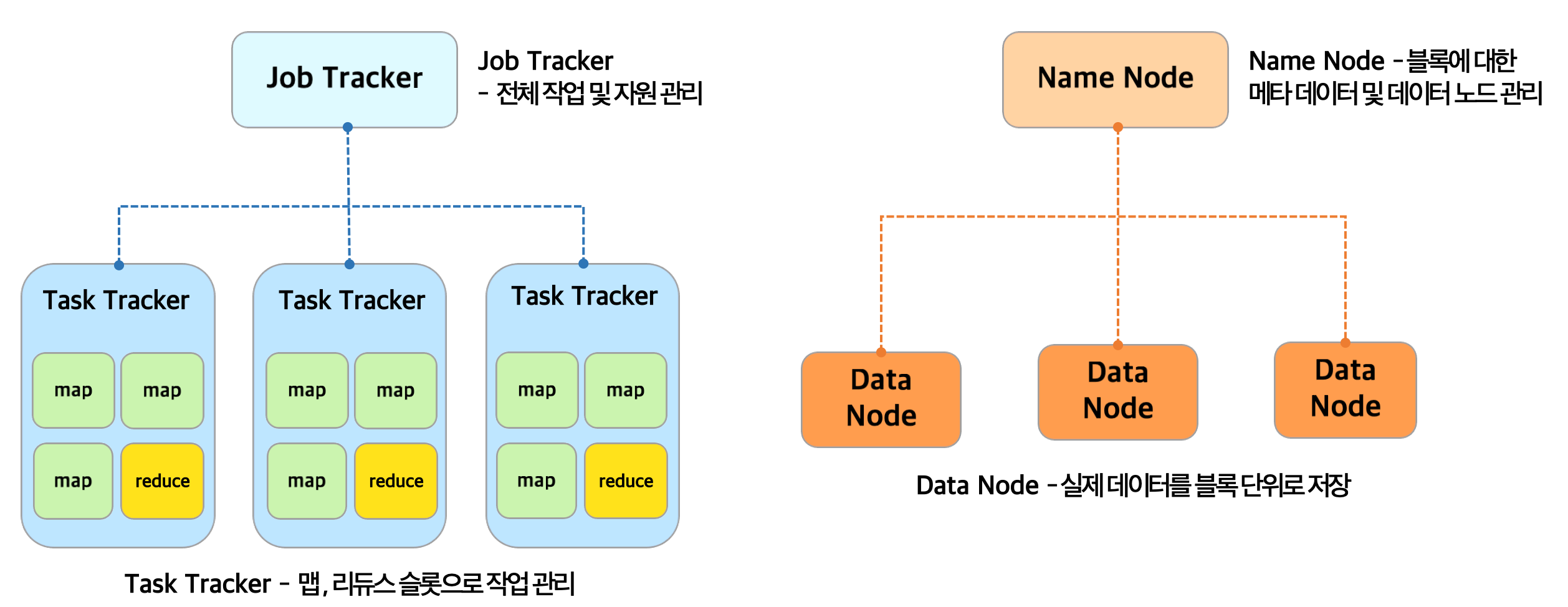
데이터 분산 저장 with HDFS
- 데이터를 블록(block) 단위로 나눠 분산 저장하는 HDFS 도입
- HDFS 내에서 네임 노드와 데이터 노드의 역할을 구분하여 데이터를 관리한다.
- 네임 노드(name node)는 블록에 대한 메타 정보를 관리하며 데이터 노드(data node)는 실제 블록 단위의 데이터를 저장한다.
- 데이터 노드(data node)는 나눠진 블록을 3개로 복제(=3copy)하여 서로 다른 서버에 저장함으로써 데이터의 유실을 방지한다.
- (HDFS에 대한 자세한 내용은 아래 페이지 참고) https://developers-haven.tistory.com/47
HDFS(Hadoop Distributed File System/하둡분산파일시스템)에 대하여
1. HDFS(Hadoop Distributed File System) HDFS(하둡분산파일시스템)란? 데이터를 블록(block) 단위로 나뉘어 분산 저장하는 파일 시스템을 의미한다. 버전에 따라 기본적인 블록 사이즈는 64MB~256MB이며 원하는
developers-haven.tistory.com
병렬 처리 with Job & Task Tracker
- Client로부터 데이터 읽기, 쓰기 등의 요청이 들어오면 데이터를 병렬 처리하는 작업이 필요하다.
- 이러한 작업을 전체 총괄하는 담당자와 실제 작업 수행자를 분리시켰는데 이러한 역할을 하는 것이 각각 잡 트래커(Job Tracker)과 태스크 트래커(Task Tracker)이다.
- 잡 트래커는 전체 작업 진행상황과 자원(=작업을 처리하기 위한 CPU, 메모리 같은 자원을 의미)관리를 담당한다.
- 태스크 트래커는 맵, 리듀스 슬롯을 통해 실제 작업을 관리한다. (데이터를 처리하는 과정에 따라 리듀서의 개수는 달라진다)
여기서 잠깐! 맵, 리듀스, 슬롯이 무엇인지 잠깐 설명하고 넘어가겠다.
맵리듀스(map-reduce)는 데이터를 처리하기 위한 일종의 프로그래밍 모델이다. HDFS에서는 블록 단위로 데이터가 존재한다고 설명했었는데, 블록들에 대해 작업을 처리(map)하고 이 결과물을 모아서 집계(reduce)하게 된다. 이때 슬롯은 맵, 리듀스를 수행하는 작업 처리 단위를 의미한다고 보면 된다. 더 쉽게 설명하자면 태스크 트래커는 잡 트래커로부터 자원을 할당받아서 맵 슬롯, 리듀스 슬롯을 통해 작업을 처리한다.
Hadoop v1의 문제점
- 병렬 처리 과정에서 맵, 리듀스 슬롯의 역할이 한번 정해지면 해당 작업이 종료될 때까지 용도를 바꿀 수 없다.
- 그렇기 때문에 작업이 없음에도 슬롯이 무한대기하는 '병목현상'이 발생하게 되는데 이를 해결하기 위해 하둡 v2가 등장하게 되었다.
Hadoop V2 (Yarn 도입)
Hadoop v1에서 작업 시작 전에 맵 슬롯과 리듀스 슬롯 역할을 정해주면서, 해당 슬롯에 작업이 넘어오기 전까지 슬롯이 무한대기하는 '병목현상'이 발생하게 되었다. 이러한 문제를 해결하기 위해 Yarn architecture를 도입하여 Hadoop v1의 Job Tracker 역할을 분리하게 되었다. 참고로 v1의 작업 단위는 잡(Job)이고, v2의 작업 단위는 애플리케이션(application)이라는 점을 참고하여 아래 설명을 읽으면 된다.
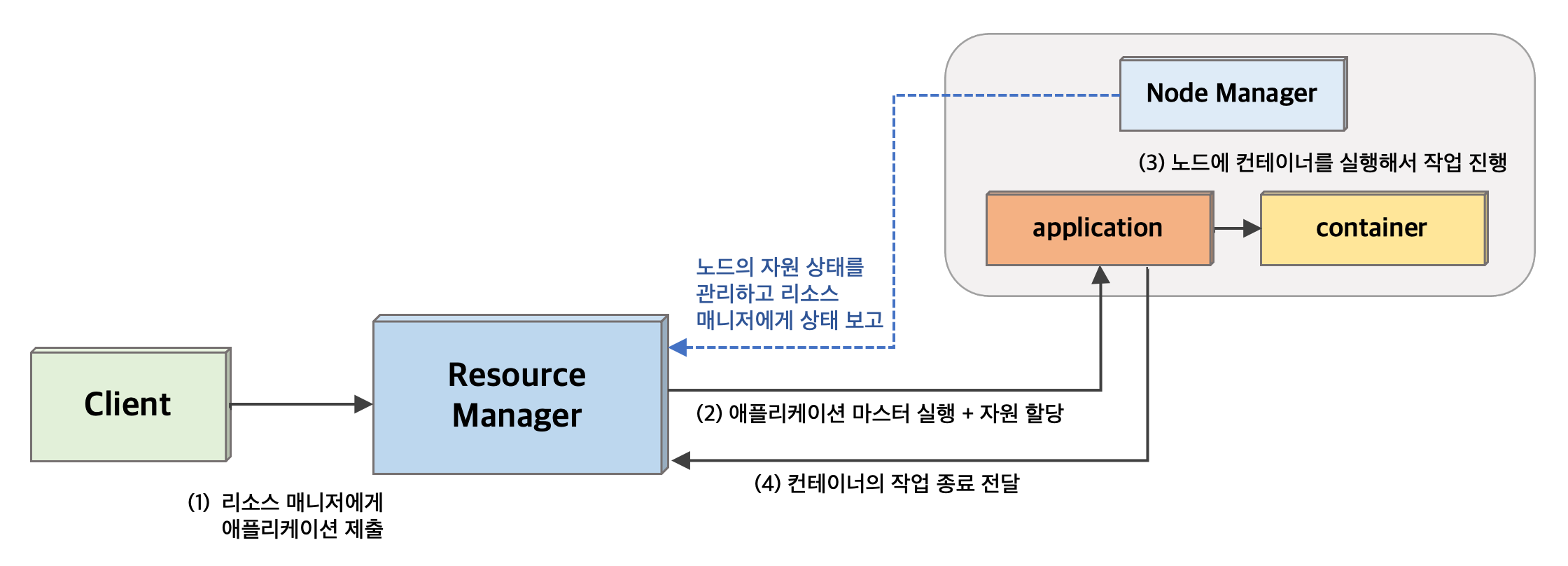
Yarn은 어떻게 잡 트래커의 역할을 분리했을까?
- 하둡 v1에서는 잡 트래커가 전체 작업 및 자원 관리
- ➔ 자원 관리를 리소스 매니저와 노드 매니저가 담당
- ➔ 애플리케이션(=작업) 관리를 애플리케이션 마스터와 컨테이너가 담당
리소스 매니저와 노드 매니저의 역할
- 기존에 잡 트래커의 자원 관리 역할을 리소스 매니저 & 노드 매니저가 담당한다.
- 리소스 매니저(Resource manager)는 노드 매니저에게 자원 상태를 보고 받으면서 전체 클러스터 자원을 관리하고 할당한다.
- 노드 매니저(Node manager)는 클러스터 노드의 자원 상태를 관리하고 리소스 매니저에게 자원 상태를 보고한다.
애플리케이션 마스터와 컨테이너의 역할
- 기존에 잡 트래커의 작업 관리 역할을 애플리케이션 마스터 & 컨테이너가 담당한다.
- 애플리케이션 마스터(Application master)는 애플리케이션의 라이프 사이클을 관리한다.
- 컨테이너(Container)는 자원을 할당받아 실제 작업을 처리하는 주체이다.
하둡 V1에서 잡 트래커가 모두 담당하던 역할을 (리소스 매니저/노드 매니저/애플리케이션 마스터/컨테이너)로 분리하게 되면서 더 효율적인 자원과 작업 관리를 할 수 있게 되었고 슬롯의 병목현상 문제를 해결할 수 있게 되었다. 용어와 역할이 조금 생소할 수 있지만 기존 V1에서의 역할을 V2의 어느 부분이 담당하는지에 대해서 살펴보다보면 조금 이해가 쉬울 것이다.
Hadoop 작업 지원 도구
위에서 하둡의 버전별 특징에 대해서 살펴보았는데, 이번에는 하둡 내에서 작업과 모니터링을 위한 기능적 요소를 더 알아보도록 하자.
Distcp(Distribute Copy)
- 클러스터 내에서 맵 리듀스를 통해 대규모 파일을 병렬 복사해주는 기능
- 대규모 데이터를 이동시키기 위해 Distcp 기능을 사용하며 네트워크 자원을 많이 사용하기 때문에 네트워크 사용량을 모니터링하면서 맵의 개수를 늘려가줘야 한다.
하둡 아카이브(Hadoop Archive)
- 쪼개서 존재하는 작은 파일을 블록 사이즈로 묶어서 관리하고 사용할 수 있도록 도와주는 기능
- 작은 사이즈의 파일이 늘어나면 네임 노드에서 관리하는 것이 어려워지기 때문에 하둡 아카이브 기능을 사용하여 쪼개진 파일을 묶어서 관리하는 과정이 필요하다.
이번 시간에는 하둡의 구조(architecture)와 여러 기능에 대해서 살펴보았다. 처음 내용을 접할 때는 조금 어려운 부분이 많을 수 있지만 앞장에서 설명한 HDFS 내용과 반복해서 보다보면 전체적인 구조를 이해하는데에 도움이 될 것이다. 오늘도 많은 사람들에게 유용한 정보가 되었기를 바랍니다!
참고: [빅데이터-하둡,하이브로 시작하기] WikiDocs
https://wikidocs.net/book/2203