지난 시간에는 스파크 자료구조의 RDD에 대해서 알아보았다. 만약 아직 보지 못했다면 아래 페이지를 참고하도록 하자. 이번 시간에는 또 다른 자료구조인 DataFrame, DataSet에 대해서 알아보도록 하자.
2023.11.09 - [[기술공부]/BigData] - Apache Spark 자료구조 - RDD
Apache Spark 자료구조 - RDD
지난 시간에 스파크의 등장배경과 아키텍처 구조에 대해 살펴보았다. 아직 보지 못했다면 아래 페이지를 참고하도록 하자. 이번 시간에는 스파크 자료구조 중 하나인 RDD에 대해서 자세히 알아
developers-haven.tistory.com
🔎 Spark Application 구현방법
Spark v1 → RDD
Spark v2 → DataFrame, DataSet
<DataFrame>
1. DataFrame에 대하여
▪️ 컬럼이 존재하는 2차원 데이터로, 쉽게 스키마를 가진 RDD라고 생각하면 된다.
▪️ SQL 쿼리를 이용하여 데이터를 쉽게 처리할 수 있는 것이 특징이다.
2. 코드 예시(python)
예시 - json 파일을 이용하여 DataFrame을 만들어서 실습해본다. (ex.스키마정보, 조건필터링, sql쿼리사용법)
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate() # DataFrame은 SparkSession 객체 사용
sc = spark.sparkContext
df = spark.read.json("/content/sample_data/anscombe.json") # json file 사용
# DataFrame 확인
print(type(df))
# 데이터 확인
df.show()
# 스키마 정보 확인
df.printSchema()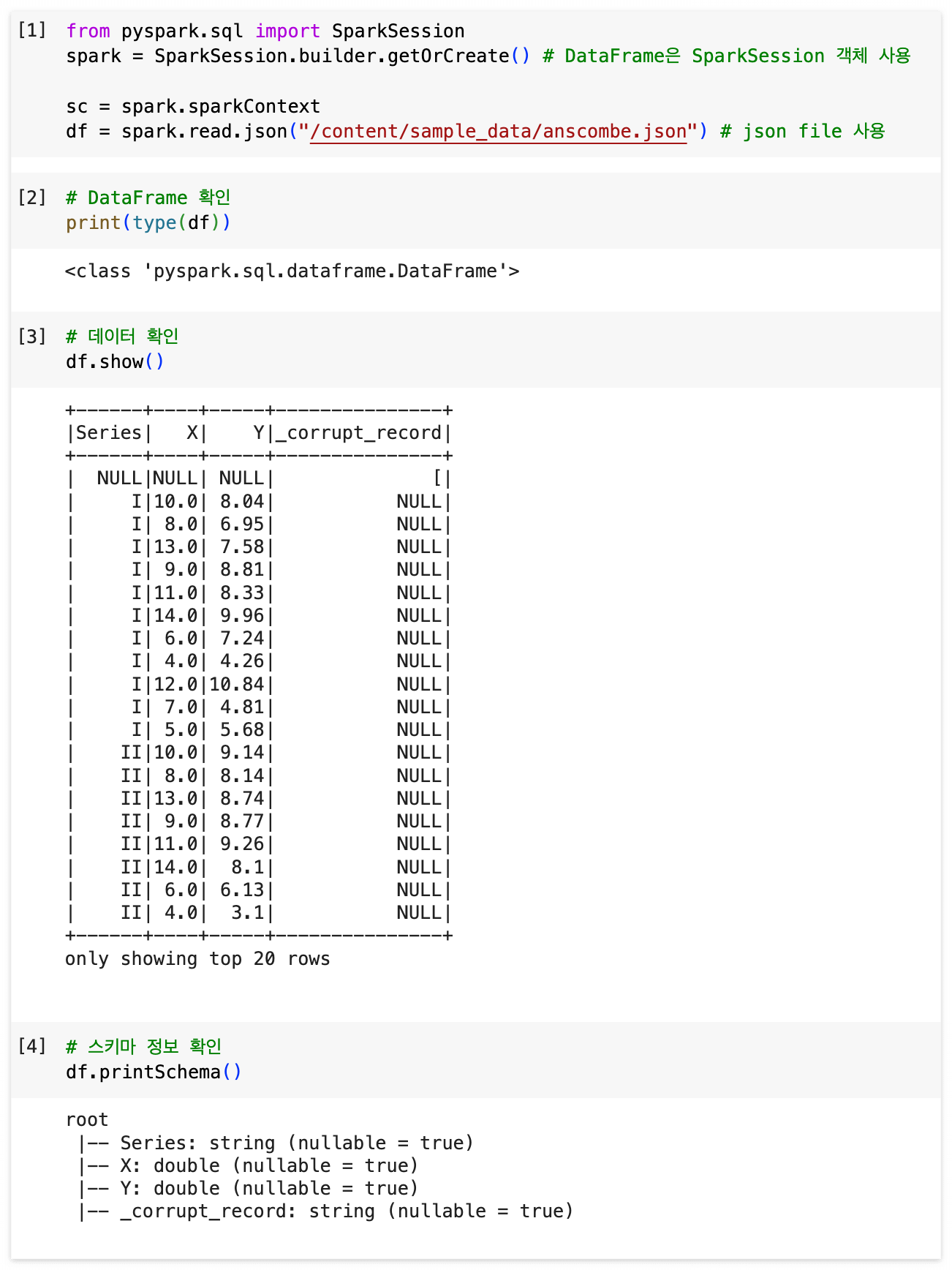
# 조건에 맞는 데이터만 필터해서 보기
df.filter(df.X > 10.0).show()
# 데이터프레임을 sql로 사용하기 위해서는 데이터프레임에 이름을 정해줘야 한다.
df.createOrReplaceTempView("test_table") # 데이터프레임을 test_table이란 뷰로 등록
# sql 쿼리
# Series가 Null값인 것을 제외하고 Series별 X,Y의 평균 확인 (단, 소수점은 첫번째 자리까지만 표시)
result = spark.sql('''select Series, round(avg(X),1) as avg_X, round(avg(Y),1) as avg_Y
from test_table
group by Series
having Series is not null
order by Series asc''')
# sql 결과 확인
result.show()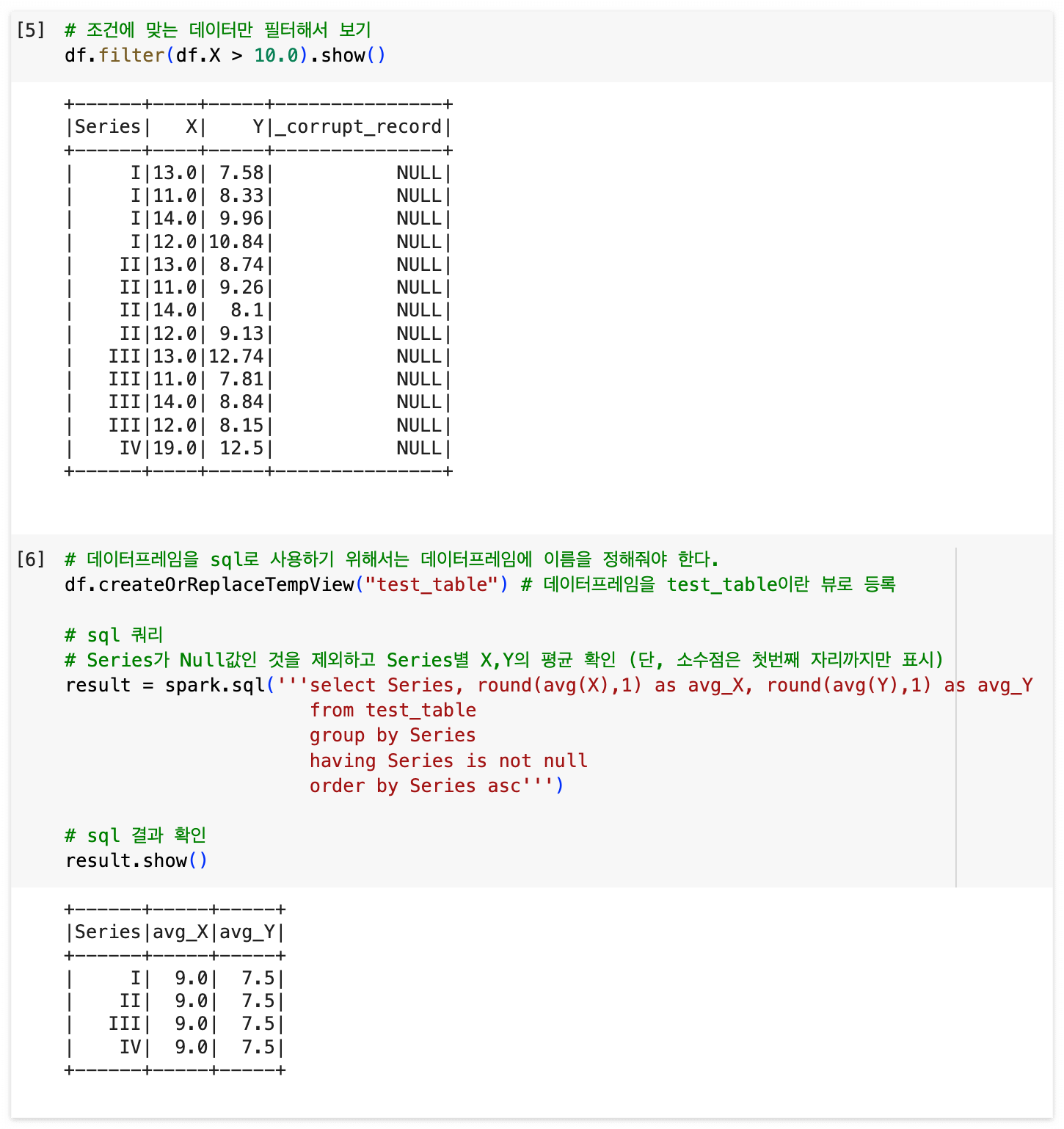
<DataSet>
1. DataSet에 대하여
▪️ 타입을 가진 컬렉션으로 타입의 안정성이 중요할 때 사용한다.
▪️ 데이터에 접근할 때마다 row 포맷이 아닌 사용자가 정의한 데이터 타입으로 반환해준다.
▪️ JVM을 이용하는 scala, java에서만 사용 가능하다. (실습에서는 scala이용)
2. 코드 예시(scala)
(1) case class를 이용해서 DataSet을 직접 정의하여 컬럼으로 데이터를 조회할 수 있도록 한다.
import org.apache.spark.sql.SparkSession
// make 'People' cass class
case class People(name: String, age: Long, salary: Int)
val people = Seq(People("David", 30, 1500),
People("White", 25, 2000),
People("Tomas", 30, 2500),
People("Elain", 27, 3000),
People("Jenny", 25, 3200))
val peopleDS = people.toDS()
peopleDS.show()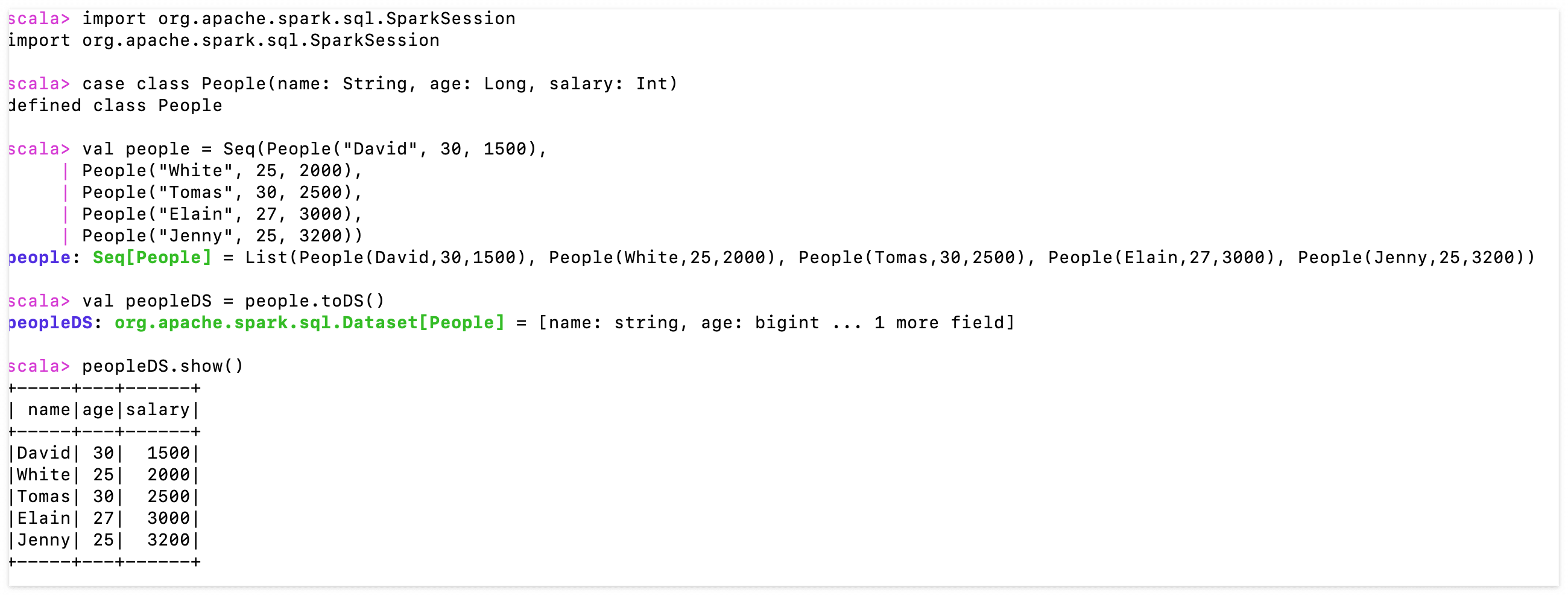
(2) DataSet을 이용한 데이터 연산 예시 (DataFrame과 동일하다)
// schema print
peopleDS.printSchema()
// select 'name' column only
peopleDS.select("name").show()
// filtering, over 2500 salary
peopleDS.filter($"salary" > 2500).show()
// grouping with age
peopleDS.groupBy("age").count().show()
// grouping with age, find salary's average
peopleDS.groupBy("age").avg("salary").show()
// order by salary with desc
peopleDS.orderBy(col("salary").desc).show()
(3) view를 생성하고 SQL 쿼리를 이용하여 원하는 데이터를 조회해본다.
// make view named people
peopleDS.createOrReplaceTempView("people")
// sql query, find average salary grouped by age
spark.sql("""SELECT age, avg(salary)
FROM people
WHERE salary IS NOT NULL
GROUP BY age""").show()
이번 시간에는 RDD에 이어서 DataFrame, DataSet에 대한 내용과 실습을 직접 해보았다. 특히 DataSet의 경우 자바와 스칼라 언어만 지원을 하다보니 나의 경우는 스칼라를 이용했다. 최대한 이해를 더 쉽게 할 수 있도록 실습 과정마다 주석으로 설명을 적어두었으니 한번씩 실습을 따라해보는 것을 추천한다. (실습에서 사용한 json 파일은 함께 첨부했으니 참고하길) 총 3번의 시간에 걸쳐서 스파크와 자료구조에 대해서 알아보았는데, 업무를 하며 궁금했던 것들이 많이 해소될 수 있었던 시간이었다. 누군가에게도 이 글이 궁금증을 해소하는데에 도움이 되었으면 좋겠다.
참고 사이트
https://wikidocs.net/28531
https://blog.naver.com/pjt3591oo/222724676035
'[기술공부] > BigData' 카테고리의 다른 글
| Apache Spark 자료구조 - RDD (0) | 2023.11.09 |
|---|---|
| Apache Spark에 대하여 - 등장 배경과 아키텍처 (0) | 2023.11.09 |
| Hive(하이브)에 대하여 (0) | 2023.08.23 |
| Hadoop(하둡)에 대하여 (0) | 2023.08.22 |
| HDFS(Hadoop Distributed File System/하둡분산파일시스템)에 대하여 (0) | 2023.08.21 |