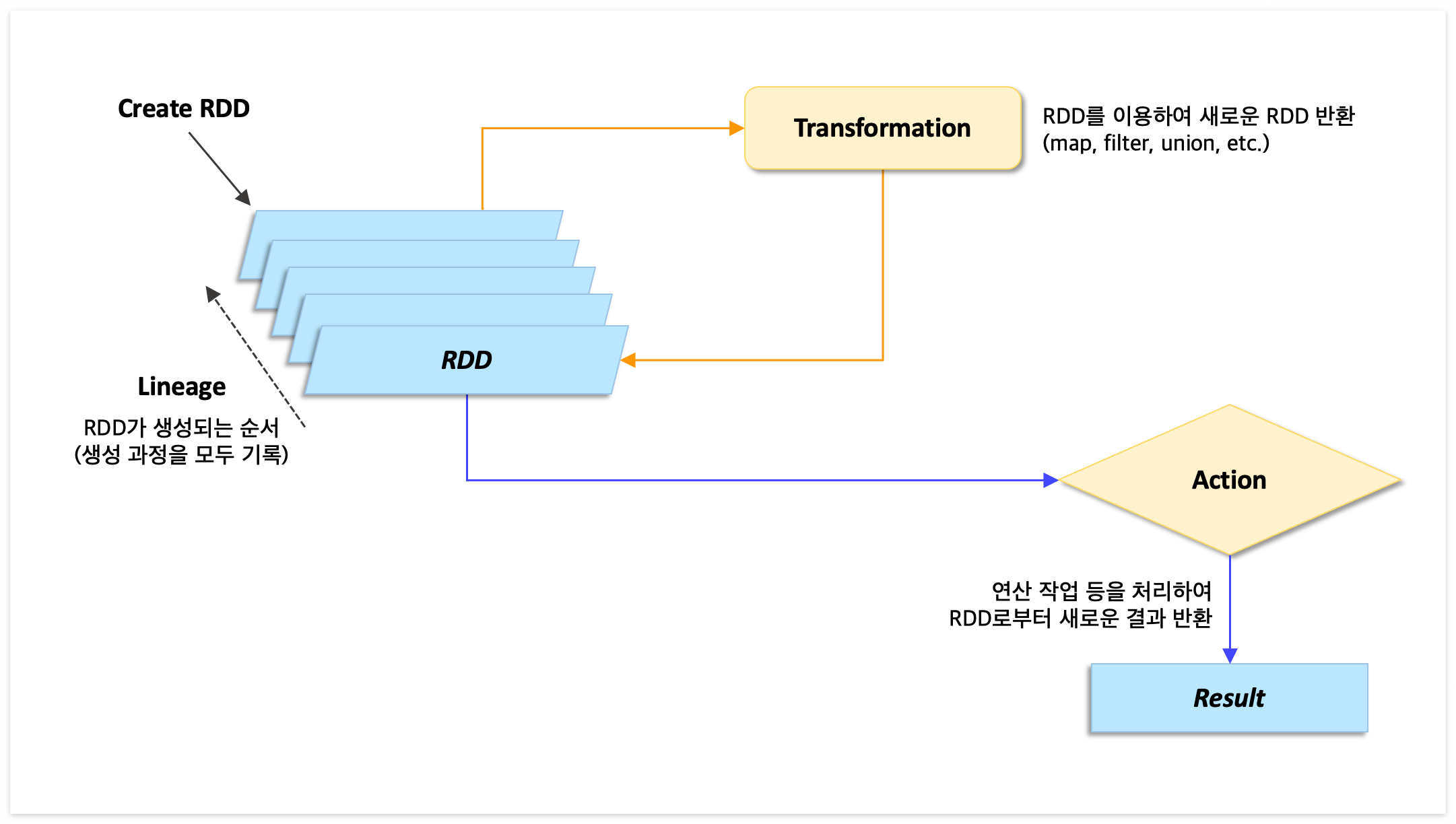
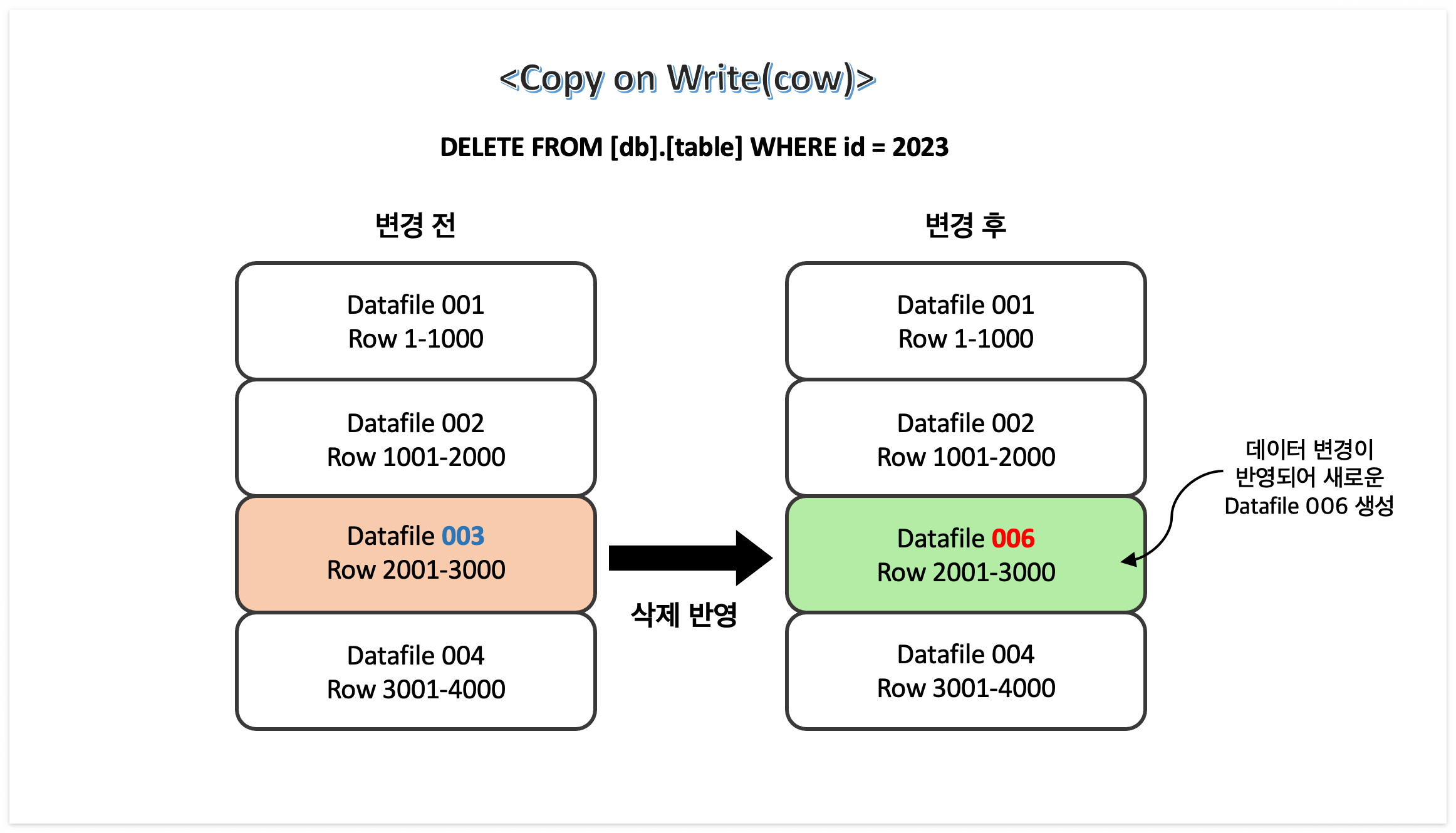
지난 시간에 스파크의 등장배경과 아키텍처 구조에 대해 살펴보았다. 아직 보지 못했다면 아래 페이지를 참고하도록 하자. 이번 시간에는 스파크 자료구조 중 하나인 RDD에 대해서 자세히 알아보도록 하자. 2023.11.09 - [[기술공부]/BigData] - Apache Spark에 대하여 - 등장 배경과 아키텍처 Apache Spark에 대하여 - 등장 배경과 아키텍처 대규모 빅데이터를 저장하고 처리하기 위해 Hadoop이 등장하게 되었지만 시간이 지나면서 성능적으로 아쉬운 부분이 생기게 되었다. 하둡의 이러한 부분을 보완하기 위해 등장한 것이 Apach Spark이 developers-haven.tistory.com 🔎 Spark Application 구현방법 Spark v1 → RDD Spark v2..