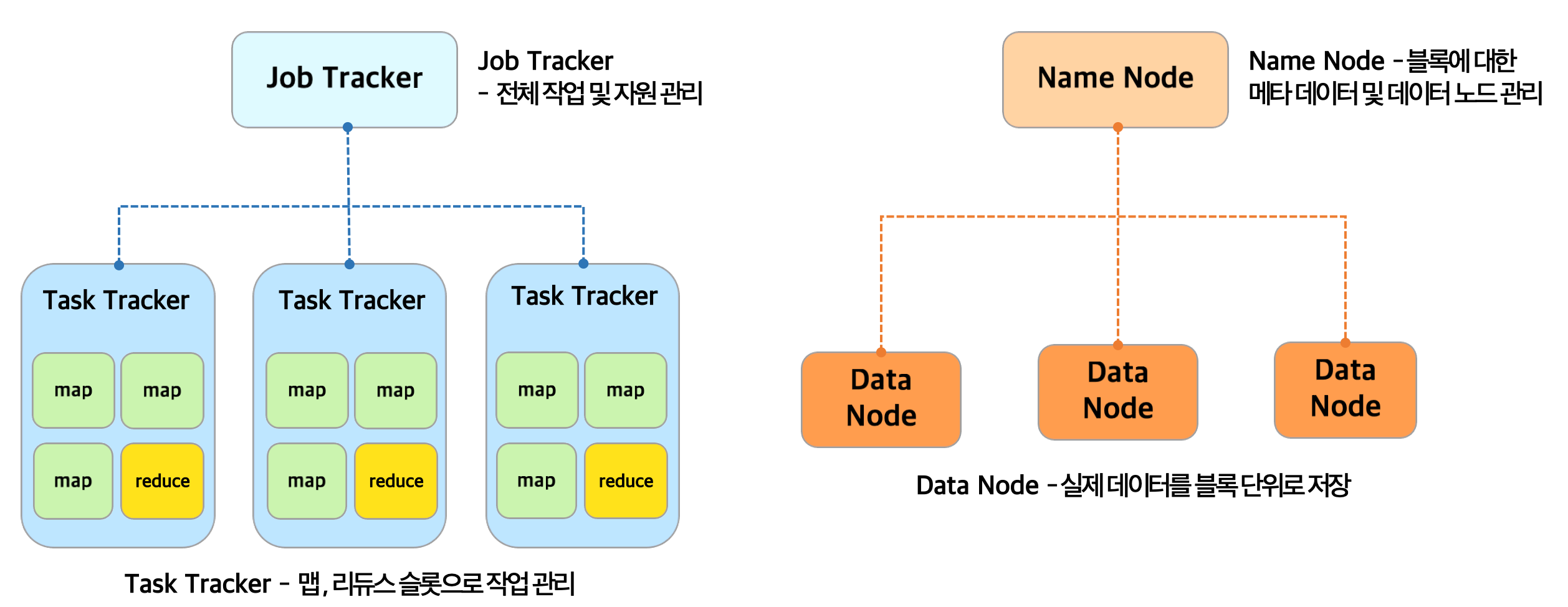
지난 시간에 Iceberg의 구조에 대해서 자세히 알아보았는데, 혹시 못봤다면 아래 페이지를 참고하도록 하자. 이번 시간에는 Iceberg의 특징 및 사용법을 알아보려고 한다. (참고로 관련쿼리는 Spark기준으로 작성했다) 2023.10.11 - [[기술공부]/Data] - Apache Iceberg란 무엇일까? Apache Iceberg란 무엇일까? 현재 빅데이터 솔루션 기업에서 Data Architect로 근무하면서, 새로운 기술이 우리 회사의 솔루션에 적용될때마다 자연스레 많은 기술 공부의 기회를 얻고 있다. 작년에 진행한 프로젝트에서 Iceberg developers-haven.tistory.com Iceberg를 관리하는 방법 # Compaction 데이터가 많이 쌓이는 테이블은 메타데이터도 ..