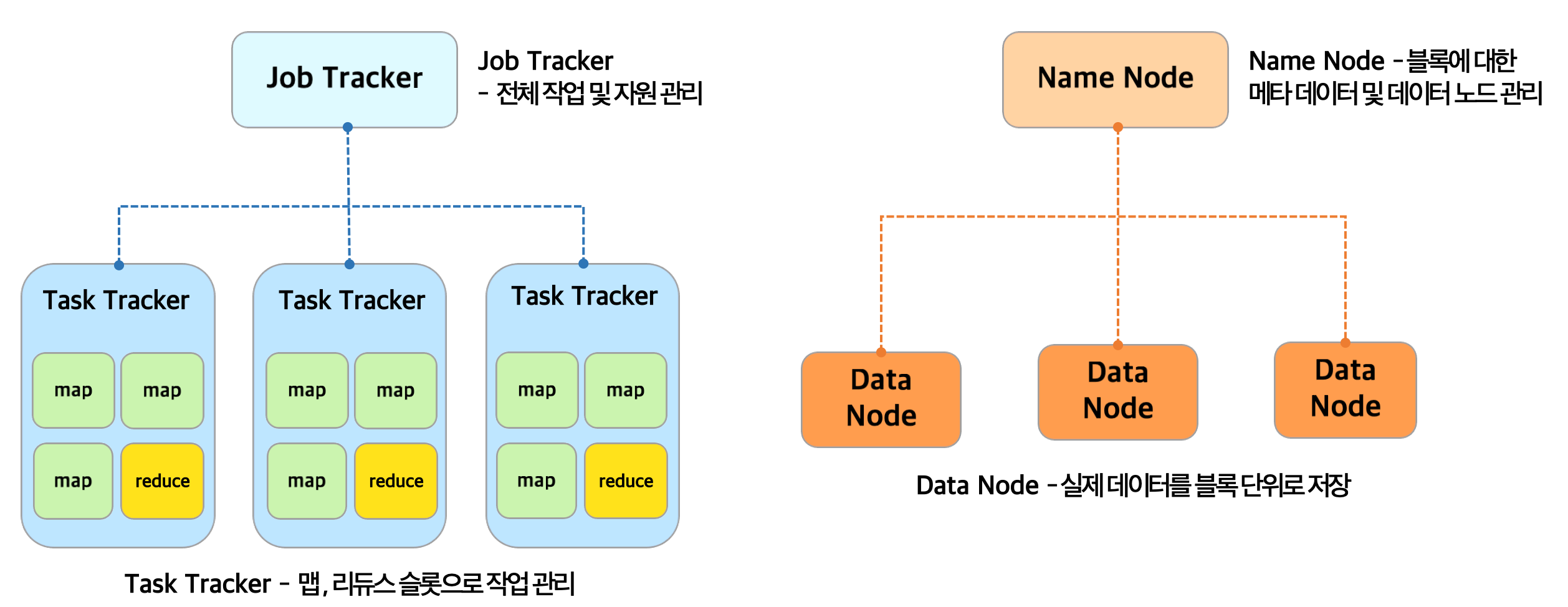
하둡이란 무엇일까? 빅데이터 환경에서 일을 하다보면 Hadoop(하둡)에 대해서 한번쯤은 들어보거나 실제 하둡 환경에서 작업해봤을 것이다. 하둡에 대한 가장 보편적인 정의는 프로그래밍을 통해 컴퓨터 클러스터에서 대규모 데이터를 분산 저장 및 처리할 수 있는 프레임워크이다. 데이터를 분산 처리하면서 데이터 분석을 위한 비용과 시간을 단축시킬 수 있었고, 하둡의 등장으로 빅데이터 분석이 본격적으로 시작되었다. 시간이 지나면서 데이터를 더 효율적으로 처리하기 위해 하둡 버전도 기능을 업그레이드했고, 22년 말 기준으로 버전3(v3)까지 공개되었다. 하둡의 가장 큰 특징은 '분산 저장과 처리'라고 할 수 있는데 처음 접하는 사람에겐 조금 생소한 표현일 수 있다. 이를 좀 더 자세히 이해하기 위해서 하둡의 버전별..